
A quick introduction: by day, I'm a DevOps Engineer at Red Gate, a software company in Cambridge, UK. Outside of work, I enjoy both amateur radio (hence the callsign, M0VFC) and community broadcast radio at Cambridge 105. This blog aims to span all those interests - so feel free to ignore the posts that aren't relevant!
Feel free to get in touch on Twitter (@rmc47).
73 / Best wishes,
Rob
For some years, there's been a lack of any very good VHF / UHF multi-mode radios available in the amateur market. Plenty of rigs will "do" 2m or 70cm SSB, but if you're intending to use them as part of a moderately serious station, they tend to be lacking, either in cleanliness of the transmitted signal, or the ability to cope with very strong signals from other stations while being able to receive a much weaker signal.
It's certainly a challenge: as DF9IC wrote, to cope with the very strongest stations on receive requires handling signals 130dB above the noise floor, which represents an amazing dynamic range. Nothing that I'm aware of meets that requirement, but worse, the best radios on the market today are still inferior to those produced some decades ago. The state of the art should not have regressed.
My own drive for improved performance comes from contesting with G3PYE/P: our normal portable location is less than 10km from several active amateurs, and we have close to line of sight between our antennas. Any imperfections in one of our transmitted signals can bring misery to everyone else.
The most common option for good V/UHF performance now seems to be a transverter. This uses a good HF transceiver to produce an intermediate frequency signal, often on 28MHz, and increases that, linearly, to the wanted operating frequency - 144 or 432MHz, for example.
There are now a number of HF radios with excellent performance from nearly all the major manufacturers: Elecraft's K3, Icom's IC-7300 or IC-7610, Flex's 6700, and Kenwood's TS-590 or TS-890. These all have very clean transmitted signals and handle equally strong signals on receive.
But which transverter to add to that? There's now a few on the market for 70cm:
Costs vary hugely from less than $50 to in excess of $1000. But does the performance match the price?
A disclaimer: I'm not an RF engineer. I have some basic test equipment, and the benefit of a few friends who are much smarter than me who've been kind enough to share some of their knowledge. Any mistakes are entirely mine. Some of the results below might be limitations in my test setup, though I believe the comparative results are likely to hold true.
IF: Elecraft K3, serial #6167, with new KSYN3A synthesisers. 28MHz at <=1mW out from transverter output, either constant carrier or 2-tone test using internal generator.
Spectrum analyser: Rigol DSA-815TG with 30dB attenuator (entered as ref offset, so dBm values shown should be reasonably accurate).
![]()
I originally purchased this as a kit in 2013, before the launch of the G4DDK Iceni, but took some years to actually complete it. It produces a nominal 25W out, though tends to get rather less linear as you approach that.
Wide sweep:
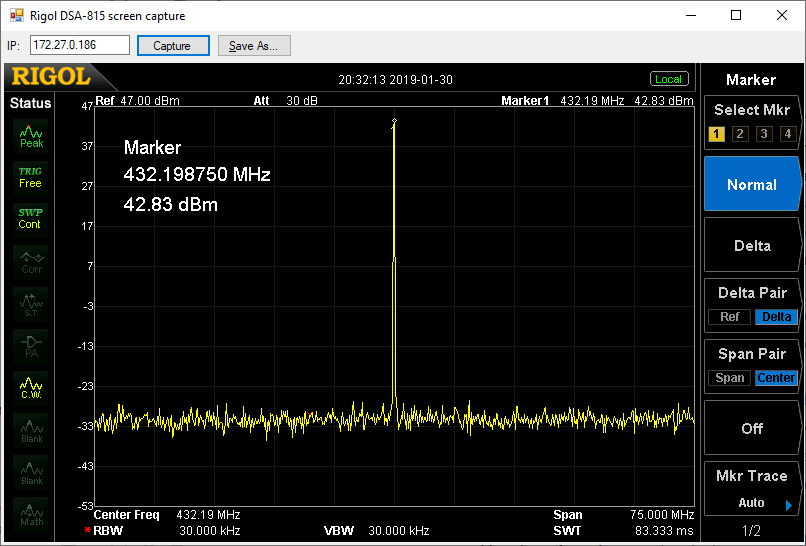
Nothing noteworthy. Wanted signal in the right place, and nothing else visible.
IMD3 (a good indication of how linear the device is):
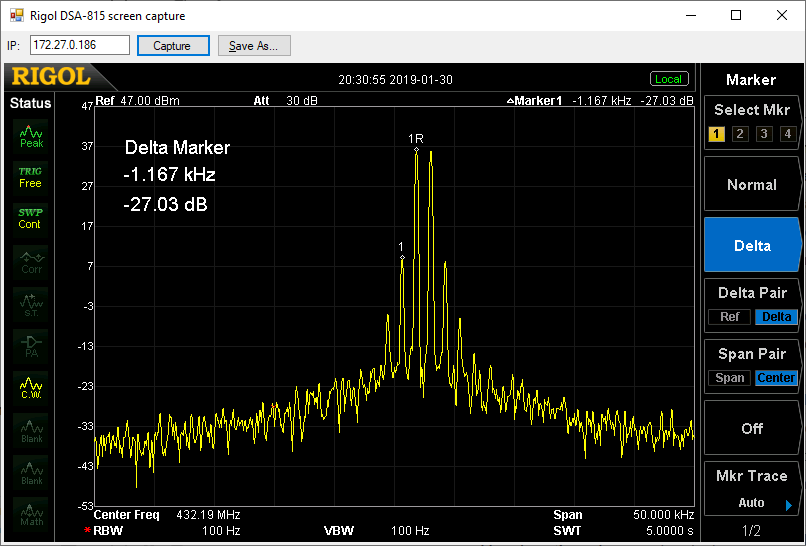
Acceptable (at about 10W output), -27dB relative to each tone. Though I'd still file under "could try harder": here's the IF signal at 28MHz for comparison:
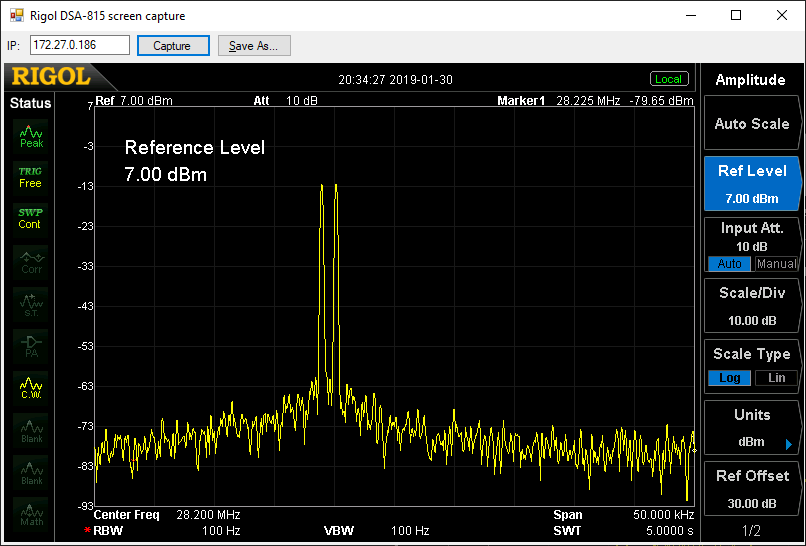
Here, there's nothing visible at all apart from the two wanted carriers. Remember this is from the 1mW transverter output of the K3: doing the same test at 100W would not be anywhere near as good. If your radio does have a dedicated transverter output, use it if possible!
I bought this from their eBay shop purely on the grounds of price and curiosity. It claims 3-4.5W out, but 1mW drive wasn't enough to achieve this, even with the output power adjustment at maximum.
Wide sweep (@0.5W output):
![]()
A little different to the DEMI! As well as the wanted signal at 432MHz, two other large peaks are visible. The lower one is at 404MHz, corresponding to the transverter's local oscillator, and the higher at 460MHz, corresponding to the LO plus twice the IF. Both of these are due to inadequate filtering: the DEMI uses helical filters with a very narrow bandwidth, but these aren't cheap.
(There's also a smaller peak at 429MHz. I'm not sure where this came from, and I couldn't reproduce it in a later test, so it can probably be ignored.)
Looking at absolute levels, how much of a problem are these unwanted signals likely to be? Using the transverter on its own, the 460MHz signal is around 4mW, which probably won't go too far on a small antenna. But if you combine this transverter with a linear amplifier to achieve the UK legal limit of 400W for the wanted carrier, the unwanted one is suddenly in excess of a watt, well outside the amateur bands and in Business Radio territory. This carries a definite risk of making you unpopular with your RF neighbours!
IMD3 @ supplied output level:
![]()
Here, the unwanted third-order intermod products (shown at marker 1) are less than 22dB down on the wanted tones - nearly four times stronger than on the DEMI. There are also a lot more higher-order tones visible.
Reducing the output power considerably does improve the linearity a lot, but at this point, the output power is only a few milliwatts:
![]()
At this lower output power, the LO and LO+2IF leakage is still present, at a similar relative level:
![]()
As a toy transverter to start playing a bit on 70cm, it's probably usable, but clearly the much lower price requires cutting some corners.
I have an Iceni kit from Sam, G4DDK, still to build, and I'll repeat these tests on that. Sadly I can't quite justify the >$1000 cost of the Kuhne transverter, so that will probably remain a gap!
Another aspect of performance that would be interesting to compare is phase noise: aside from the intermodulation products, how much unwanted signal is produced in-band, but further away from the wanted signal? I don't have a good way of measuring that at ~100kHz spacing, but if somebody can suggest one, I'd be happy to try.
Hot on the heels of of Radio Local, Strawberry Fair is one of Cambridge 105 Radio's biggest outside broadcasts of the year. We run one of the live music stages of the UK's largest free music festival, focussing on local artists ranging from solo acoustic acts to full ska and rock bands.

During the 12 hour broadcast, we hosted 16 artists. We're fortunate to have an excellent team which allows us to do this while having seamless broadcast coverage throughout:
The split of "live" and "broadcast" is something we started a couple of years ago, with excellent results. It means I can do some (very quick!) sound checks with bands as they set up while the broadcast continues uninterrupted, and without me having to think about it.
From an equipment point of view, we achieve this with a Behringer X32 Compact (plus S16 digital snake) as the front-of-house mixer, and X32 Rack in Flossie, our outside broadcast van, as the broadcast mixer. FOH sends three stereo groups to the van: vocals, instruments, and drums. That allows broadcast to achieve a better balance on air, where there's no live sound from the drums or backline, without needing to do a complete remix on the fly. Broadcast sends a mixbus back to FOH with our music playout system and the presenters' radio mics that we can feed to the front of house speakers during changeovers.
Backhaul was once again primarily via IP, this time using a tethered 4G connection to the Raspberry Pi. It proved remarkably reliable, though we did have to drop back at one point to our Band 1 analogue FM link.
Over the weekend of 27-28th May, live art collaboration Hunt & Darton were commissioned to perform "Radio Local" at the Cambridge Junction as part of the Watch Out festival. Cambridge 105 Radio, as well as broadcasting the output, provided much of the equipment and engineering behind the project.

This presented some new challenges compared to many of our outside broadcasts:
As well as these, the broadcast was to run for a solid 24 hours!

At its core, audio mixing was handled by a Behringer X32 Rack in the van. This gives a compact mixer with an incredible amount of routing flexibility. We didn't need anything like the number of inputs available, but the ability to quickly route arbitrary combinations of channels to arbitrary outputs in software is excellent for this sort of event. Clean feed for the phone line? No problem. Need to reduce output to the PA speakers, but not the broadcast feed? Fine.
Another advantage of the X32 is the ability to control it over a network. In the van, we ran X32-Edit, and Hannah the producer used an Android tablet with Mixing Station XM32. This let her drive the show, but gave us the ability to jump in if we needed (very rarely - she was great!)
On stage, a Behringer S16 digital snake provided audio connectivity back to the X32 over a single Cat5E cable. Along with Ethernet and mains, that meant only three cables between the stage and the van - handy in a public space where trip hazards need to be avoided.
Audio playout used the open-source Rivendell suite, running on a laptop in the van. That meant that a complete loss of the stage feed would still retain playout capability. A VNC server on that laptop allowed three other laptops, one for each of the presenters and producer, to control it remotely. The presenters could see what was lined up next, and how long was left to run on a track, as well as firing jingles and sound effects from the cart wall.
The "jingle shed" used another laptop running Audacity, coupled with a small mixer and USB audio interface. After recording, jingles were saved into a Rivendell dropbox folder over the network, and ingested automatically.
Telephone calls were provisioned using a voice over IP line from Andrews & Arnold, and terminated on an instance of Asterisk running on a Linux server (which also handled various network routing functions). This sent incoming calls to an analogue telephone adaptor where they rang a traditional phone handset. When ready to go to air, a blind transfer to another extension moved the call to an instance of MicroSIP on the van PC. This was configured to auto-answer. Send audio was a post-fade mix bus containing all channels except the phone, and receive audio appeared as a channel on the mixer.
The broadcast output fed a Raspberry Pi with Cirrus Logic audio card running LiquidSOAP, streaming it back to the main Cambridge 105 studio over the internet.
Finally, our internet connectivity came from the Junction to the van via a pair of Ubiquiti Nanostation M5 5.8GHz WiFi links; a Ubiquiti UniFi UAP-AC Lite provided local WiFi access for variouis mobile devices, but all laptops, mixers, and so on were hard wired.
In summary, we used two mixers, seven laptops, four ethernet switches, two Raspberry Pis, one server, one tablet, and countless cables - but it all worked!